Teil 7) Multithreading in Java
Fork-Join Framework
Im letzten Artikel haben wir uns mit Futures, einem Weg, Ergebnisse von asynchronen Aufgaben auszuwerten, und CompletableFutures, der Möglichkeit, diese zu verketten, beschäftigt.
In diesem Artikel geht es um das Gegenteil. Statt Aufgaben zusammenzuführen, wollen wir sie in kleinere Teile aufbrechen, (Fork) um diese schneller bearbeiten zu können. Wenn die Teilaufgaben fertig sind, führen wir die Ergebnisse davon wieder zusammen (Join).
Ein Beispiel
Das einfachste Beispiel für ForkJoinTasks ist, wenn man eine Liste an Werten hat und alle davon in einer kommutativen Weise (beliebige Reihenfolge) zu einem einzelnen Ergebniswert kombiniert. Damit sich dies lohnt, sollte mindestens die Liste riesig sein oder die Aufgaben lange andauern. Exemplarisch addieren wir hierfür ein paar Zahlen auf:
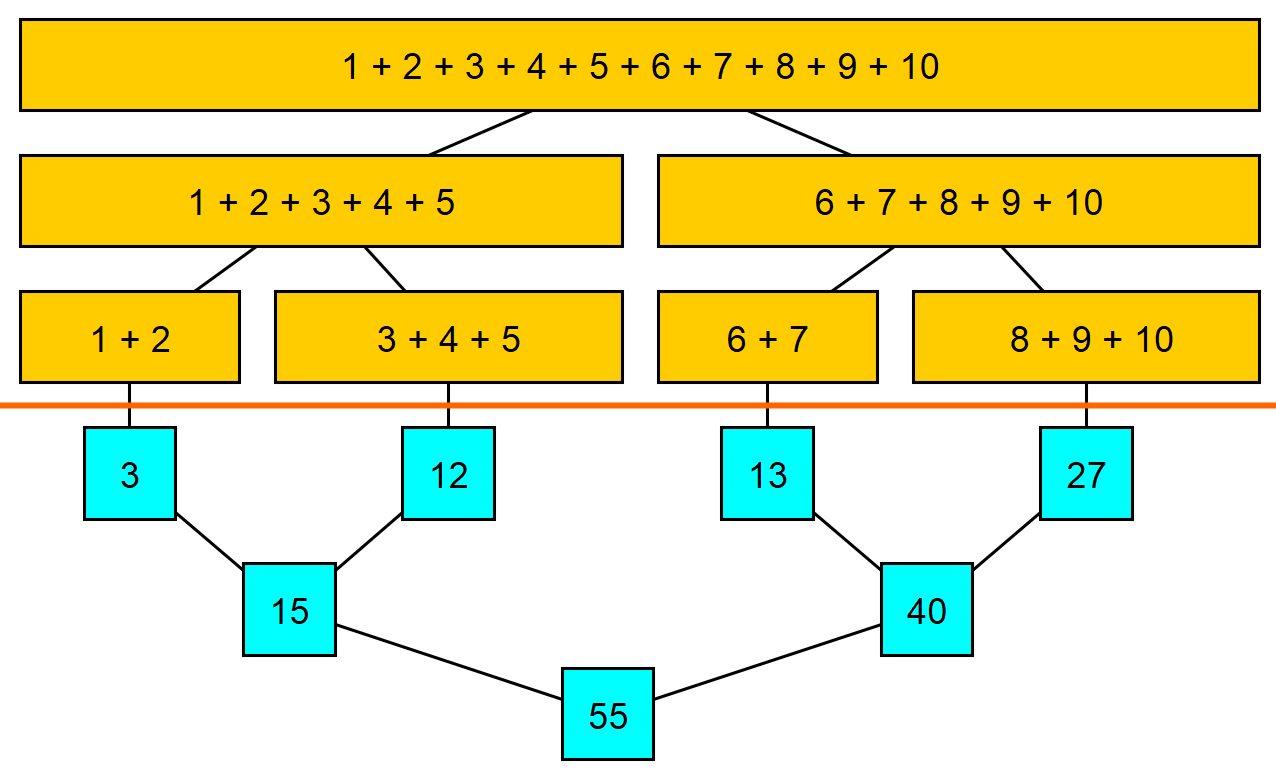 Bildliche Veranschaulichung von Fork-Join Addition. Grafik erstellt mit yEd.
Bildliche Veranschaulichung von Fork-Join Addition. Grafik erstellt mit yEd.
Der Algorithmus geht von oben nach unten. Oberhalb der roten Linie, im gelben Bereich, findet das “Forken” statt. Wir haben eine größere Addition, welche sich in zwei kleinere aufgabelt. Die Teiladditionen tun dasselbe. Im blauen Bereich werden jeweils immer zwei Ergebnisse addiert. Dies ist das Joinen beim rekursiven Aufstieg.
Implementierung
ForkJoinTasks sind Instanzen der Klasse RecursiveTask oder RecursiveAction und müssen damit nur die Funktion compute() implementieren.
In beiden Versionen können beliebige neue Aufgaben erstellt, und in “RecursiveTasks” die Ergebnisse ebenfalls kombiniert werden.
public class SumTask extends RecursiveTask<Integer> {
/// Operandenanzahl, unter der Aufgaben nicht mehr geteilt werden
private static final int THRESHOLD = 3;
/// Die gesamte Zahlenliste
private final int[] numbers;
/// Start und Endposition vom aufzuaddierenden Bereich
private final int start, end;
public SumTask(int[] numbers, int start, int end) {
this.numbers = numbers;
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
int additions = end - start;
// Wenn sich die Aufgabe zerteilen lässt...
if (additions > THRESHOLD) {
// ... definiere zwei Teilaufgaben...
int mid = start + additions / 2;
SumTask leftTask = new SumTask(numbers, start, mid);
SumTask rightTask = new SumTask(numbers, mid, end);
// GELB: Starte Teilaufgaben und warte bis sie abgearbeitet wurden
leftTask.fork(); // Führe leftTask in einem anderen Thread aus
int rightResult = rightTask.compute(); // Führe rightTask in diesem Thread aus
int leftResult = leftTask.join(); // Warte auf das Ergebnis von leftTask
// BLAU: Kombiniere die Ergebnisse
return leftResult + rightResult;
}
// ... wenn nicht: Erledige die Aufgabe sequentiell
int sum = 0;
for (int i = start; i < end; i++)
sum += numbers[i];
return sum;
}
}
Beim rightResult könnten wir ebenfalls fork() und join() ausführen,
dies jedoch direkt hintereinander zu machen hat fast denselben Effekt, wie direkt compute() auszuführen.
Der aufrufende Thread muss sowieso auf das andere join() warten und anstatt dann die Aufgabe weiterzugeben,
(Scheduling-Overhead) kann er sie auch einfach selbst erledigen.
Der CommonPool
Wir wollen unseren SumTask jetzt natürlich auch starten, jedoch ist nicht jeder ExecutorService in der Lage, mit ForkJoinTasks
umzugehen. Dafür gibt es den ForkJoinPool, eine Implementierung von ExecutorService und Executor.
Ähnlich, wie man verschiedene Threadpools mit Executors.new...Pool() erstellen kann, gibt es auch für den ForkJoinPool eine Factory.
Diese gibt uns jedoch jedes Mal den gleichen Threadpool (dieselbe Instanz), nämlich den “CommonPool” zurück.
int[] numbers = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
SumTask task = new SumTask(numbers, 0, numbers.length);
ForkJoinPool forkJoinPool = ForkJoinPool.commonPool();
int result = forkJoinPool.invoke(task);
Achtung! Der “CommonPool” wird überall in der standard-library verwendet und kann deshalb auch nicht mit shutdown() oder shutdownNow() geschlossen werden.
Wir können das letzte Codebeispiel also auch ausführen, ohne ihn überhaupt zu erwähnen:
int[] numbers = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
SumTask task = new SumTask(numbers, 0, numbers.length);
task.compute(); // ruft in unserer Implementierung fork() auf,
// welches implizit den CommonPool verwendet.
Wo wird der CommonPool noch verwendet?
CompletableFutures
Wie im Fazit des letzten Artikels schon angeschnitten wurde, verwenden asynchrone CompletableFutures, ohne explizit angegebenen Executor, den CommonPool:
CompletableFuture.runAsync(() -> task()); // Ist äquivalent zu...
CompletableFuture.runAsync(() -> task(), ForkJoinPool.commonPool());
Arrays.parallelSort
Führt eine Version von Quicksort im CommonPool aus.
Für die Implementierung des Sortieralgorithmus, siehe den unterliegenden ForkJoinTask in java.util.DualPivotQuicksort.Sorter.
Spliterators
Der Spliterator ist der etwas coolere Bruder vom Iterator. Während ein Iterator einfach nur elementweise über eine lineare Datenstruktur (Array, Collection, etc…) geht, hat der Spliterator zusätzlich noch die Möglichkeit, diese Datenstruktur an beliebiger Stelle zu spalten (split) und einen weiteren Spliterator zurückzugeben, welcher den Rest erledigt. Da jeder weitere Spliterator ebenfalls geteilt werden kann, ist der Algorithmus perfekt dafür, eine Liste, wie oben im gelben Teil der Grafik, zu partitionieren.
Nicht jeder Spliterator interagiert mit ForkJoinTasks oder dem CommonPool, jedoch gibt es eine prominente Implementierung, die darauf basiert:
Parallele Streams
Ein Stream ist eine Verkettung an Operationen, ausgeführt auf einer beliebigen linearen Datenstruktur oder Generatorfunktion (Array, Iterable, Supplier…). Wenn wir nun beispielsweise unseren Array an Zahlen haben und die obige Addition in etwas kürzerer Form mit Streams ausführen wollen, können wir einfach Folgendes schreiben:
int[] numbers = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int result = Arrays.stream(numbers)
.parallel()
.sum();
Hierfür ist kein SumTask nötig. Der Stream kümmert sich (durch das Hinzufügen von parallel()) einfach selbst darum,
dass die Elemente der gestreamten Quelldatenstruktur (hier der Array “numbers”) durch einen Spliterator gejagt,
von ihm in kleinere Ketten partitioniert, und als ForkJoinTasks in den CommonPool gegeben werden.
Hierbei schätzt der Spliterator selbst, wann es sich lohnt die Daten zu teilen.
Parallele Streams für Nerds
Für Collections#stream wird ein IteratorSpliterator verwendet, welcher für jeden trySplit-Aufruf einen ArraySpliterator mit einer wachsenden Größe zurückgibt. Erst die ersten 1024 Elemente, dann die nächsten 2028, dann 3072, usw... Die maximale Grenze liegt bei 33.554.432, also 225. Jede dieser Gruppen (Batches) wird dann im jeweiligen ArraySpliterator immer durch 2 geteilt.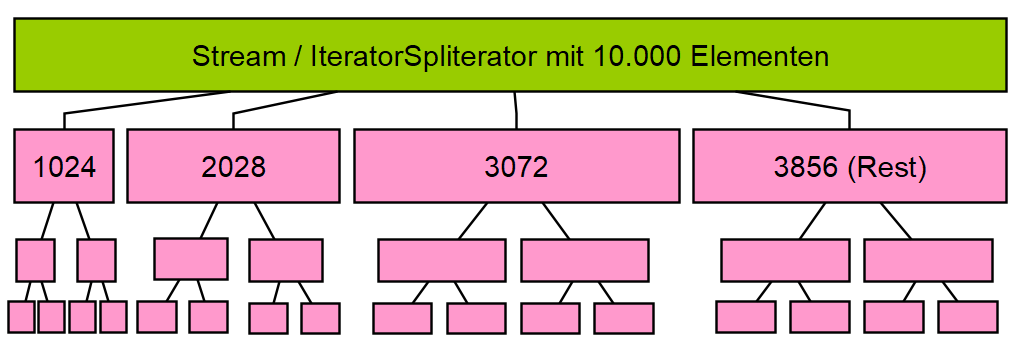 Bildliche Veranschaulichung vom IteratorSpliterator. Grafik erstellt mit yEd.
Bildliche Veranschaulichung vom IteratorSpliterator. Grafik erstellt mit yEd.
⚠️ Wichtig!
Parallele Streams sind zwar immens einfach zu schreiben, in der Praxis lohnt es sich jedoch nur in den seltensten Fällen,
sie zu benutzen, da oftmals die Datensätze einfach viel zu klein, oder die Aufgaben viel zu kurz sind.
Wenn man einen Stream mit unter 10.000 Elementen hat und triviale Operationen wie Addition darauf ausführen will, sollte man über Parallelisierung gar nicht erst nachdenken: Der Scheduling-Overhead ist immer größer als der Gewinn.
Nur, wenn der Datensatz sehr groß, und die Aufgaben sehr lang-andauernd sind, wird parallel() interessant.
Man sollte sich vor der Nutzung jedoch immer die Frage stellen: Muss dieser Code schneller werden?
Wenn ja, sollte man ausprobieren, ob es sich lohnt. Ich empfehle hier wirklich, über mehrere Ausführungen, die Zeit zu stoppen.
Fazit
Puh, das war sicher einiges an Input!
Wie wir aber wissen ist Input ein IO-Task: Wir sollten uns davon also nicht blockieren lassen und direkt mit dem nächsten Artikel über Virtual Threads weitermachen. Virtual Threads sind nämlich brandneu in Java 21 dazugekommen und bieten uns einen effektiven Weg, um viele blockierende Aufgaben mit einem hohen Durchsatz zu bearbeiten.