Für wen schreibt man Code?
Ich hatte neulich mit einem Kollegen diskutiert, was unsere Ansprüche an Code sind. Muss er nur funktionieren? Gute Fehlermeldungen werfen? Performant sein? Schön sein? Was heißt schön? Leserlich? Was heißt leserlich? Kurz und prägnant, oder ausführlich und präzise dokumentiert?
Fragen über Fragen, zu denen bestimmt jeder Entwickler eine unterschiedliche, aber nicht gleich invalide Meinung hat. Die meisten kommerziellen Softwareprojekte sind ja am Ende des Tages Teamwork, und da schreibt man ja nicht nur für sich und den Compiler, sondern vor allem auch für seine Kollegen.
Am Ende der Debatte sind wir beide jedoch an einem Codeschnipsel hängen geblieben, zu dem er so etwas sagte wie:
„Das lässt du jetzt aber nur für die Entwicklung drinnen, oder? In der Produktion kommt das raus?!“
… und ich mir dachte: “Nein, Mann. Das soll so!”, jedoch verstehen konnte, warum es eine kontroverse Entscheidung war, denn der Code infrage war so etwas Ähnliches wie:
<?php
use App\Models\Process;
assert($process instanceof Process);
?>
<label>Vorgang {{ $process->getDisplayName() }}</label>
Was ist das Problem?
Das Snippet kommt aus einer blade.php-Datei, wobei “blade” eine Template-Engine aus dem php-Webframework Laravel ist.
Mit ihr lassen sich Sektionen einer Website gliedern & ausblenden, oder auch Daten aus php-Objekten (in diesem Beispiel der “DisplayName” aus $process) in HTML einfügen.
Ein blade-Template ist also ein reines Skelett aus HTML und ein paar Ordnungsdirektiven, und selbst der eben verlinkte Wikipedia-Artikel1 sagt:
In den Templates einer Template-Engine sollte kein Programm-Code enthalten sein.
Das ganze Snippet würde übrigens auch genauso gut in einer Zeile funktionieren, …
<label>Vorgang {{ $process->getDisplayName() }}</label>
… denn der php-Interpreter geht einfach bis Laufzeit davon aus, dass alles super ist, und pfeffert einem nur dann einen Fehler um die Ohren,
wenn er $process oder getDisplayName() nicht findet.
Also die berechtigte Frage: “Warum ist also dieser Block php-Code da drin?”
Ich mag meine IDE
Ich schreibe fast alles an Code in JetBrains IDEs und diesem Fall war ich in PhpStorm unterwegs. Jeder Editor hat sicher seine Vor- und Nachteile, etwas was ich jedoch an meinem so toll finde, ist das integrierte Typsystem.
PhpStorm gibt sich Mühe, anhand vom Kontext, Datentypen und Funktionssignaturen herauszufinden, (das System dahinter heißt statische Codeanalyse), und das, ohne den Code tatsächlich auszuführen. Wenn ich also mit der Maus über einer Funktion schwebe, zeigt mir diese zum Beispiel den Doc-Kommentar an:
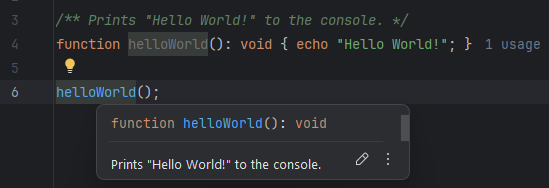
Man bekommt ebenfalls auch eine Liste der verfügbaren Methoden und Properties auf einem Objekt oder kriegt Warnungen, wenn man nicht definierte Funktionen aufruft oder null ignoriert.
Insgesamt: Sau praktisch; wäre da nicht ein kleines Problem.
Zurück zum Beispiel
Wenn man eine blade-Datei in einem Controller aufruft, kann man ihr Objekte mitgeben, die dann ausgelesen werden. In unserem Beispiel also $process:
return view('meine.blade.datei') // Öffne die blade mit dem neusten Prozess des Nutzers
->with('process', Process::where('user_id', '=', Auth::user()->id)->latest());
Hier sucht man den Prozess aus der Datenbank heraus und gibt ihm, mit dem with-Builder, den Namen 'process', mit dem er dann auch im blade referenziert werden kann.
Das kleine Problem: Da wir den Namen hier als String, also als Freitext, und nicht irgendwie als Variable übergeben, erkennt PhpStorm nicht, dass es tatsächlich ein Process ist, der nachher in der blade-Datei auftaucht. PhpStorm erkennt in der blade nicht mal, ob wir überhaupt irgendeine Variable mit diesem Namen haben und vertraut darauf, dass wir wissen, was wir tun, und es später nicht mehr anfassen.
Ich habe dieses Vertrauen nicht.
Ich weiß, dass ich mich später nicht mehr an jede Zeile Code erinnern werde, die ich je geschrieben habe und ich weiß genauso, dass ich nicht von anderen erwarten kann, dass sie das tun.
Darum also der php-Block?
In dem kontroversen Block mache ich zwei Dinge:
<?php
use App\Models\Process; // 1
assert($process instanceof Process); // 2
?>
- Als Erstes importiere ich Process explizit, sodass klar ist,
dass ich keine andere Klasse
Processmeine, die sich in irgendeinem anderen Ordner verirrt hat. BesondersBuilderoderResponseKlassen sind für so etwas immer anfällig. - In der zweiten Zeile erzwinge ich, dass ein
$processexistiert, und dass er eine Instanz der eben importierten Klasse ist. Assertions fliegen im Livebetrieb tatsächlich vollständig raus, die Performance muss also nicht unnötig leiden.
Neben diesen beiden Vorteilen kommt jetzt jedoch das Beste: PhpStorm weiß für die gesamte Datei, dass es sich um einen Process handelt und schlägt mir die entsprechenden Methoden vor.
Fazit
Ich schreibe häufiger mal Code, nur für die statische Analyse. Der Compiler braucht ihn nicht, im best-case bleibt das Programm gleich schnell, und ja, in einer Funktion, die sowieso schon etwas größer ist, kann so eine no-op auch schnell mal irritieren. Natürlich soll man auch nicht anfangen, Anfragen vom Kunden in seinen Templates zu behandeln. Dafür gibt es REST-Controller und JavaScript bzw. TypeScript.
Im Refactoring habe ich jedoch gelernt, wie viel besser es ist, wenn mir irgendwann mein Vergangenheits-Ich auf die Finger haut, als wenn ich anfange Signaturen von Code zu ändern, mir jedoch nicht bewusst bin, wo dieser genutzt wird und mich dann über plötzliche Fehler wundere. Ich bin generell ein sehr großer Fan vom Überprüfen von Datentypen, vor allem in Sprachen mit schwacher Typisierung, und bin grundsätzlich davon überzeugt, dass ein kompetenter Entwickler mehr Meta-Code schreiben sollte, wenn er damit sicherstellen kann, dass sein System über lange Zeit wartbarer wird.
Wikipedias1 Tipp wäre also meines Erachtens besser, würde empfohlen werden, dass statt “Programm-Code” keine Logik in Templates vorkommen soll.
-
Zitat vom 18.04.2024: Template-Engine ↩ ↩2